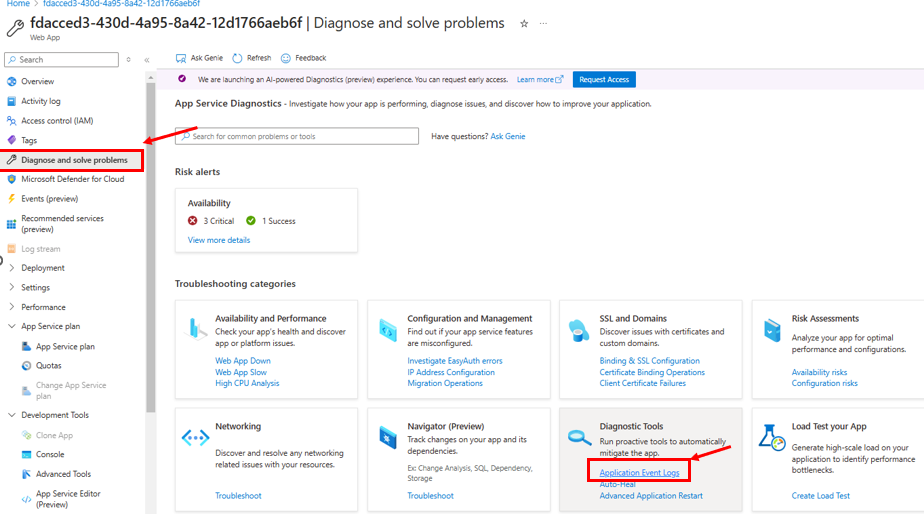
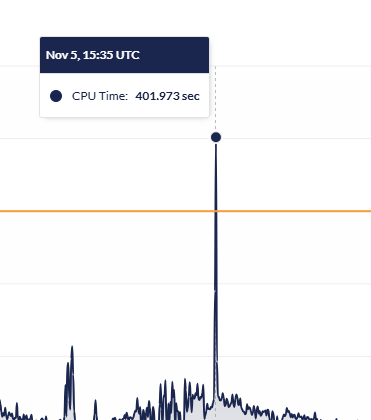
When a site goes down, it can feel urgent, but a step-by-step approach often reveals the problem quickly. Here’s a simple guide to help you troubleshoot and bring the site back online.
These initial questions can save you time by narrowing down the possible causes:
- Did they recently deploy code? New code can sometimes introduce errors, missing dependencies, or conflicts that cause downtime.
- Was there an upgrade? Major upgrades especially can cause “Bootfailed” errors due to compatibility issues.
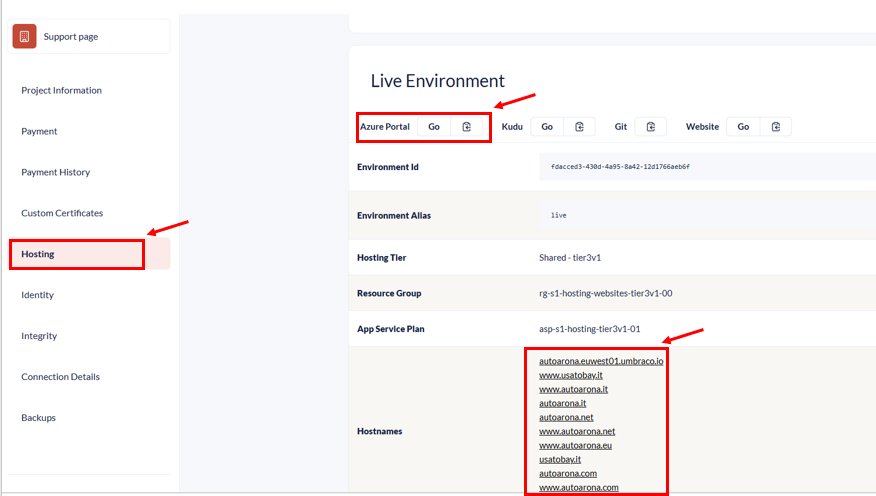
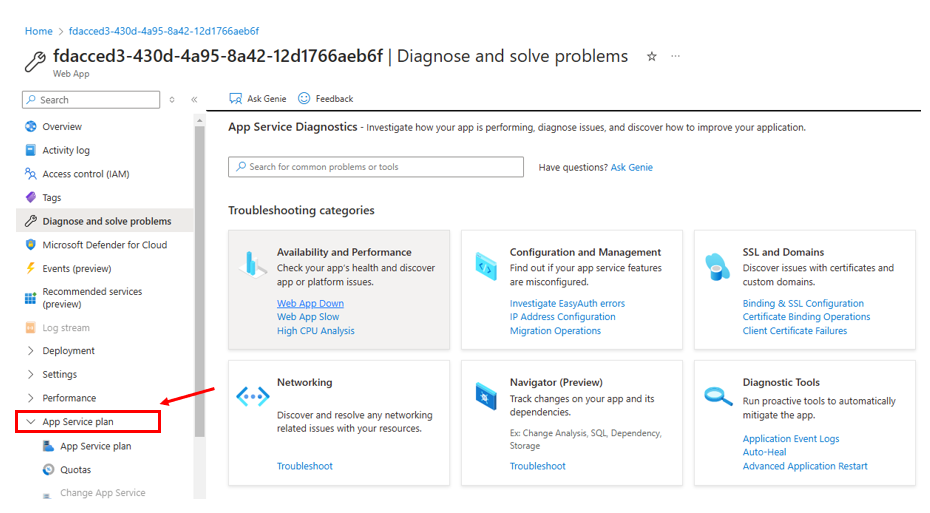
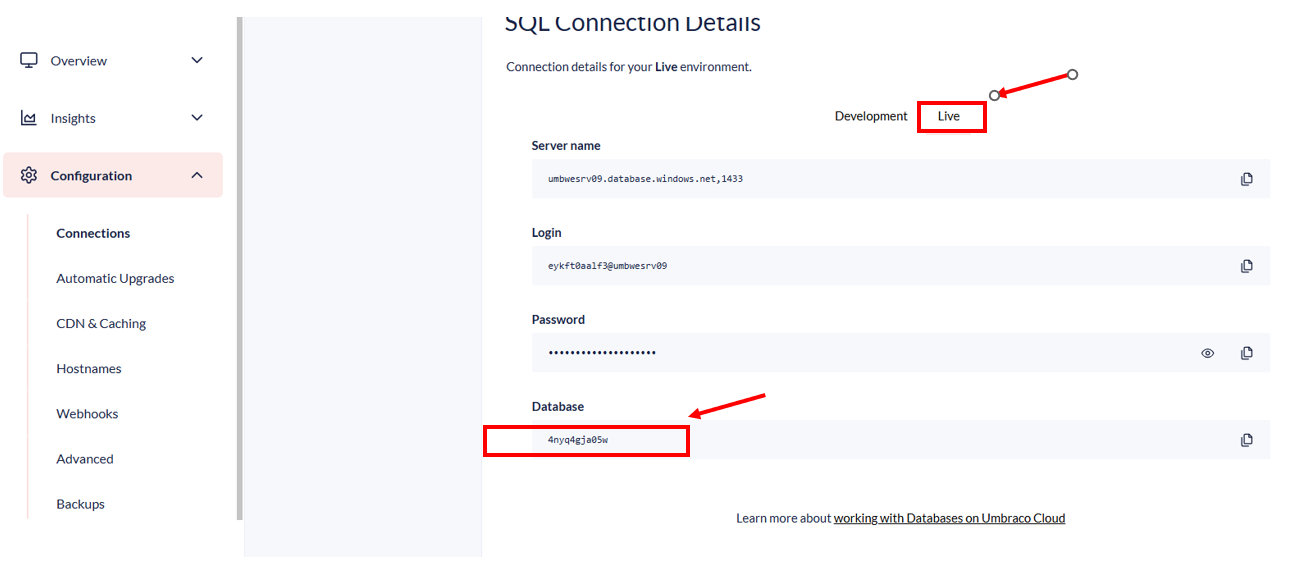
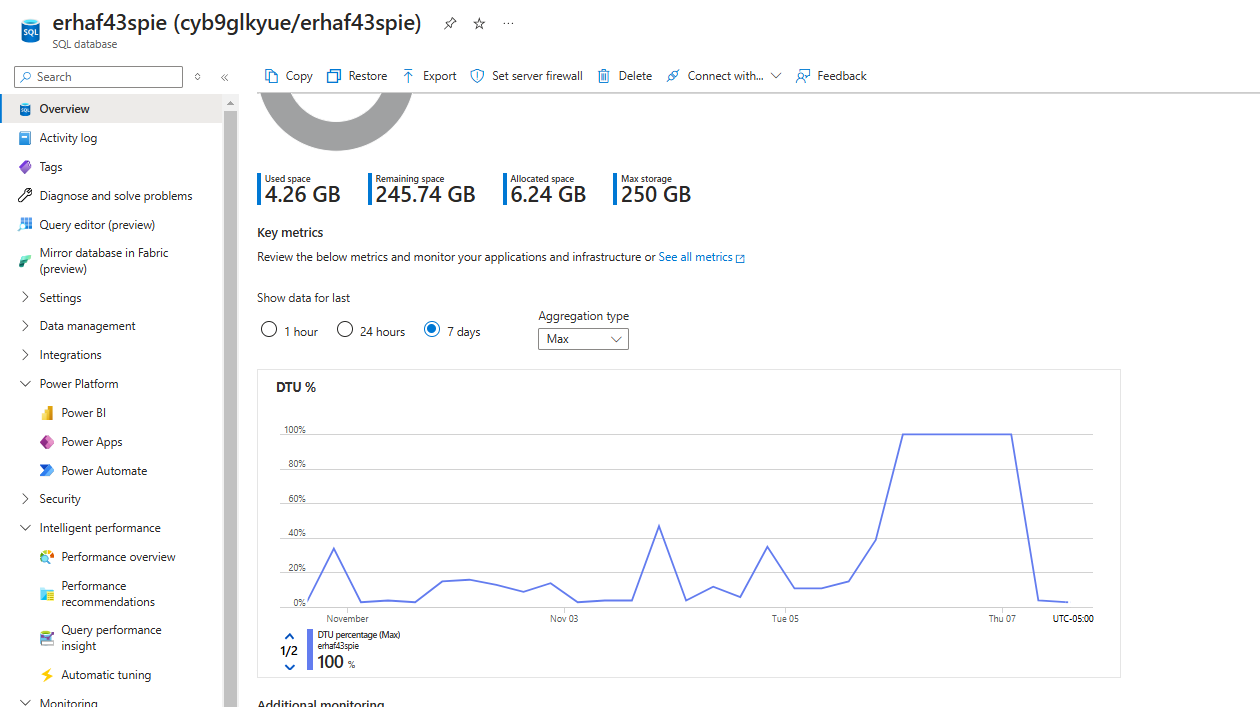
- Which environment is affected? Knowing if it’s Dev, Staging, or Production helps clarify the scope of the issue—especially if hostnames are only on Dev or specific setups are only on Prod.