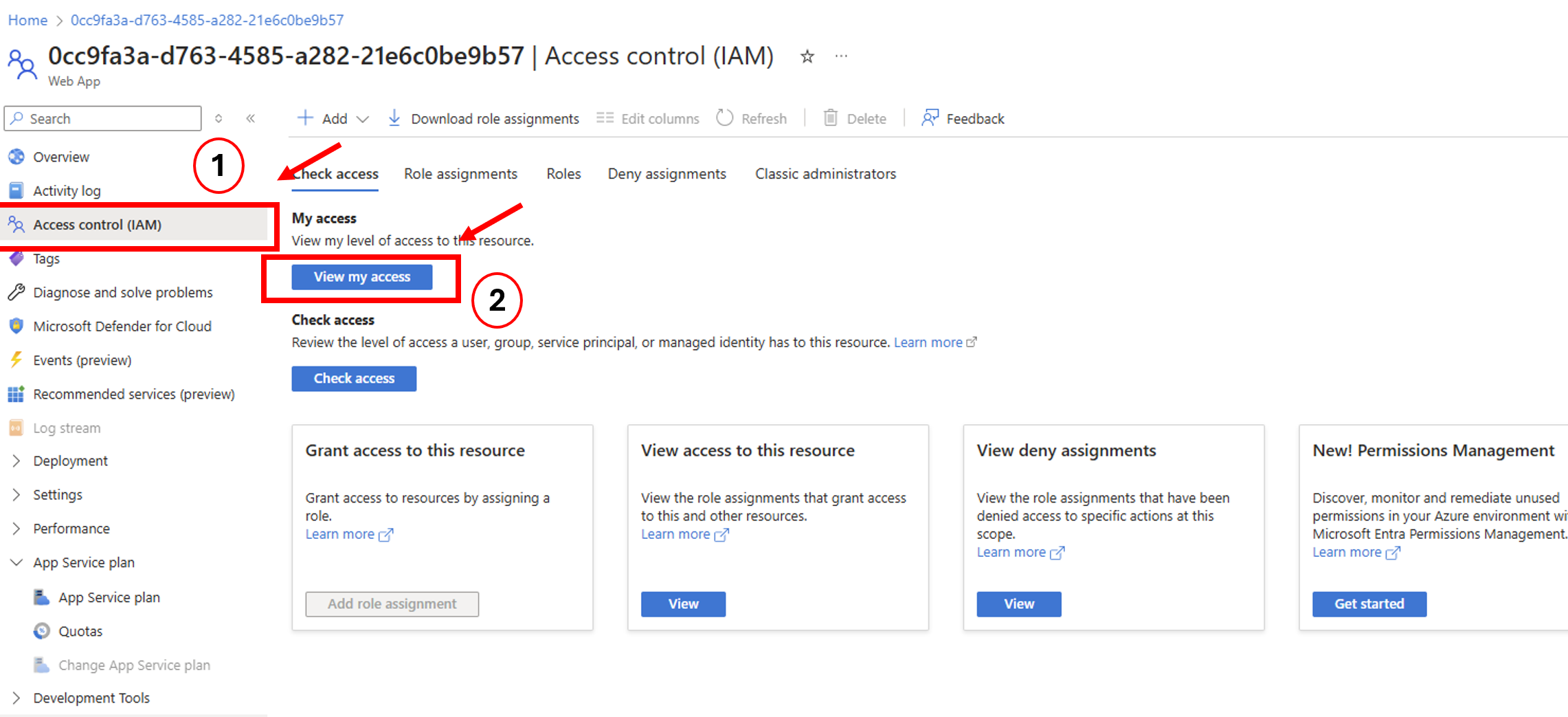
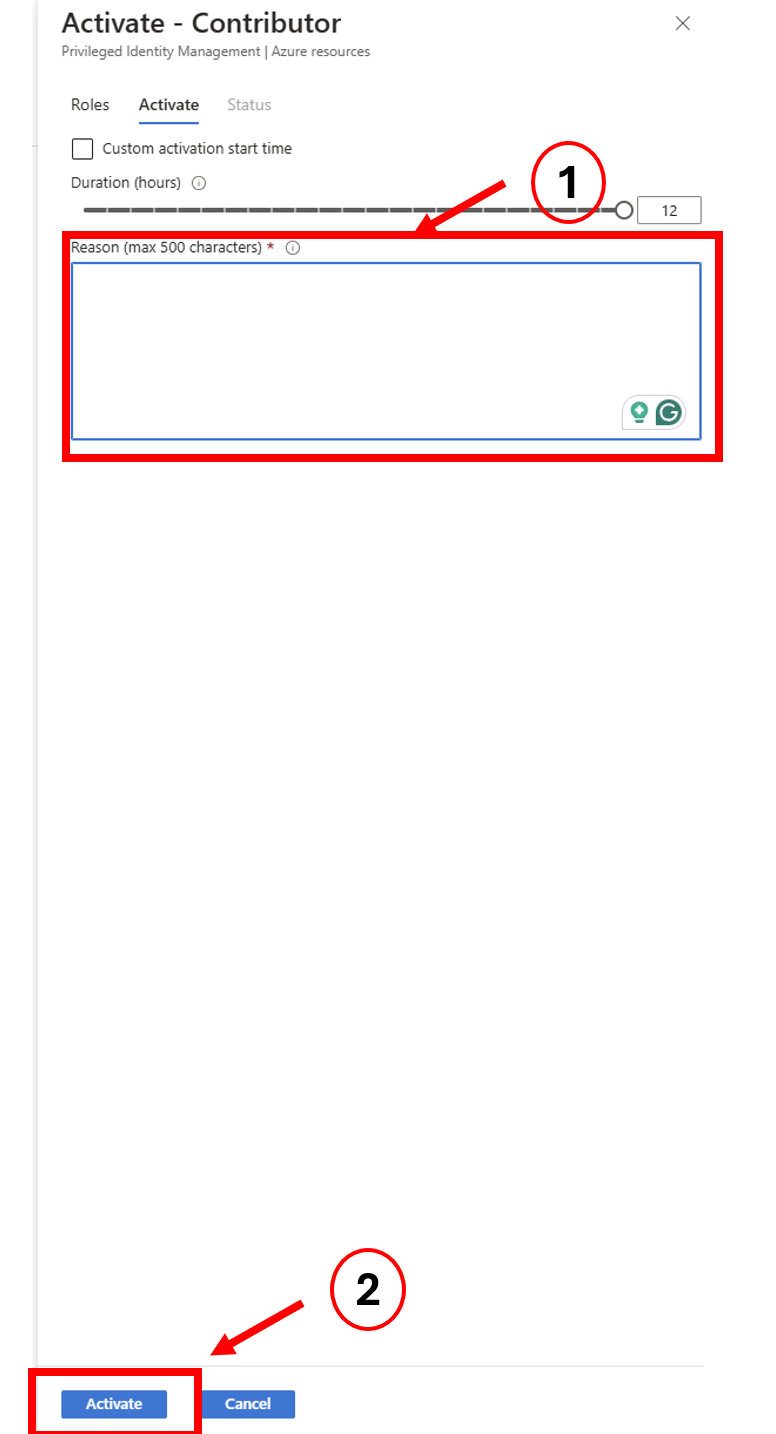
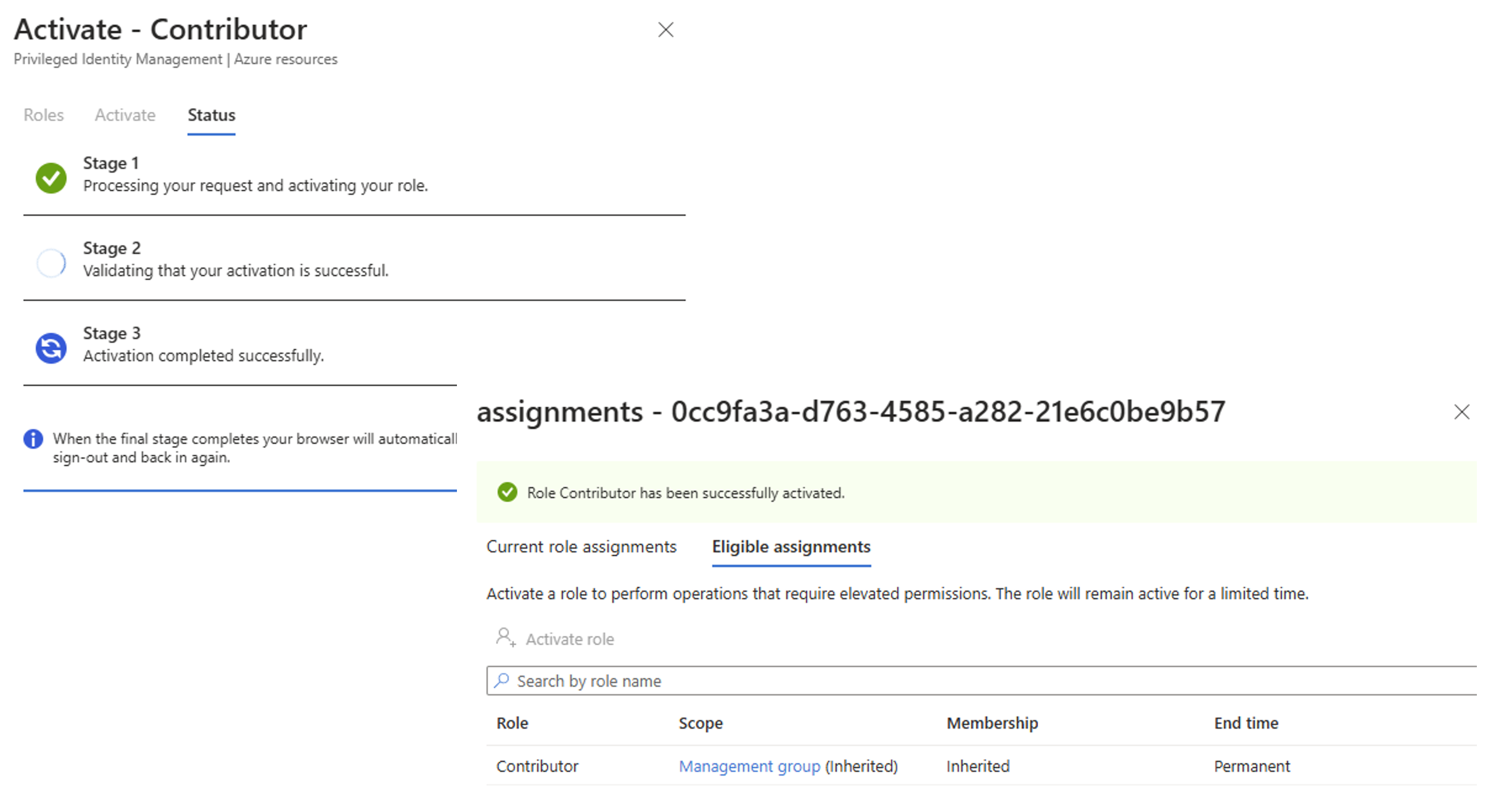
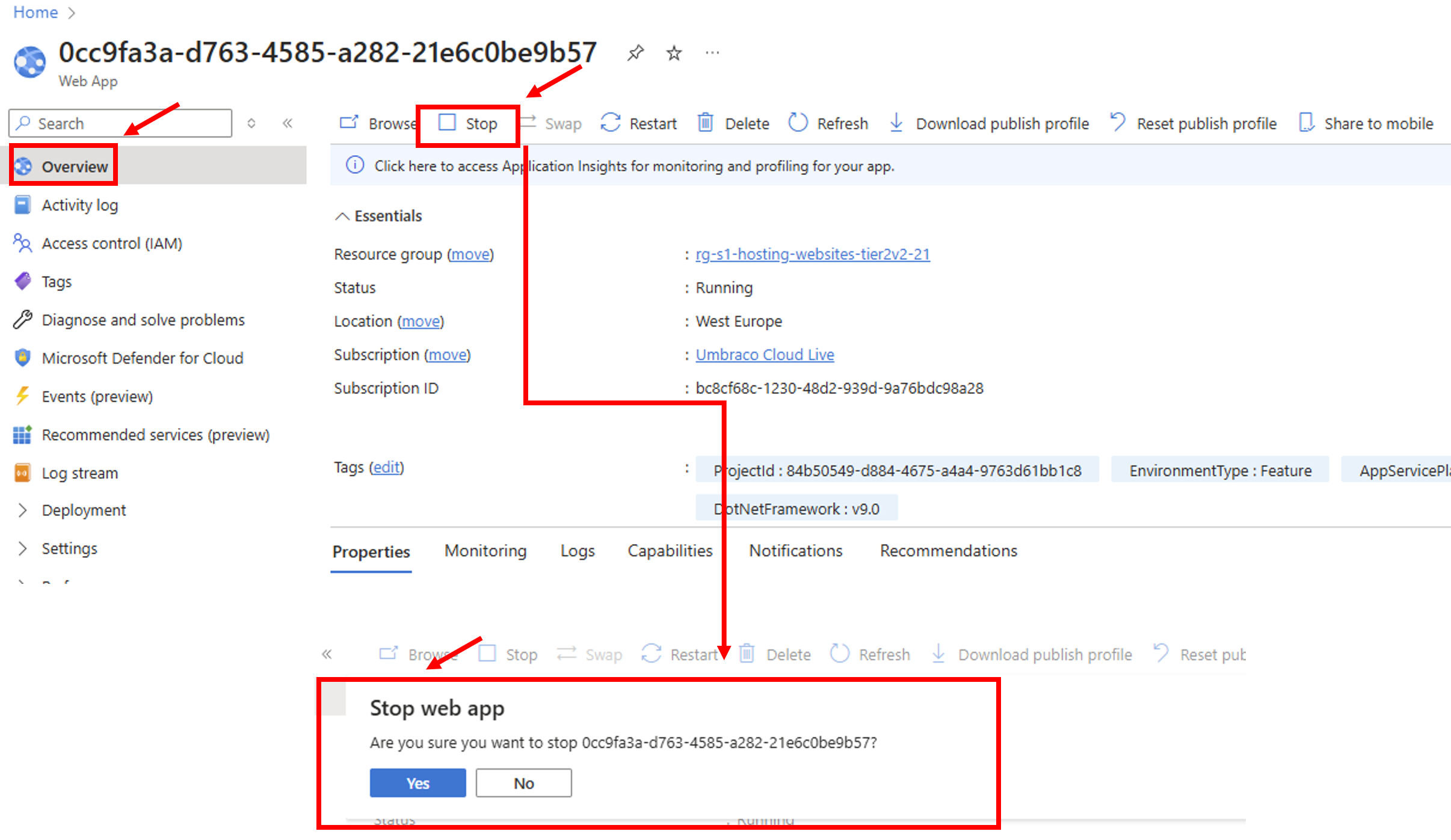
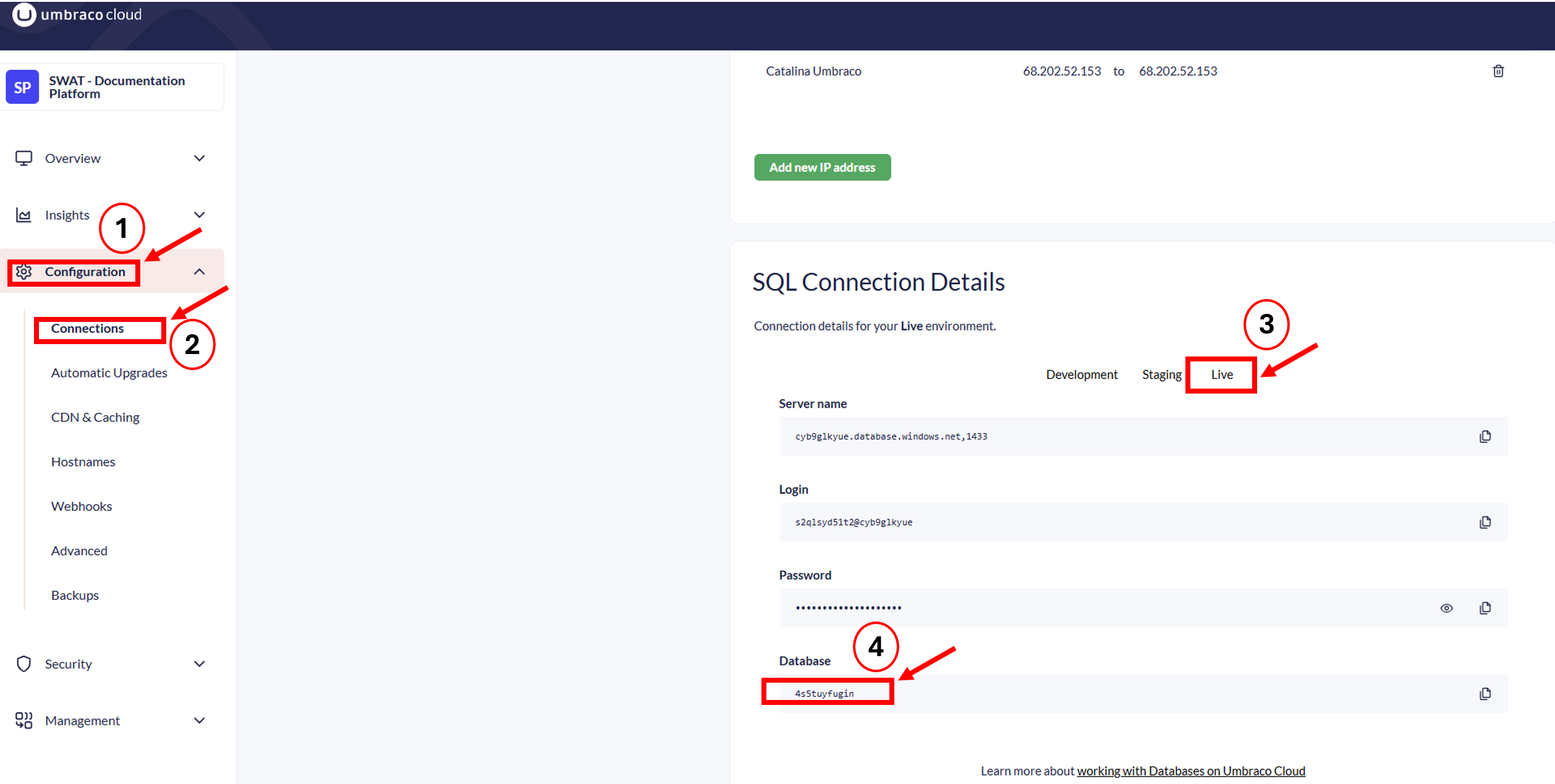
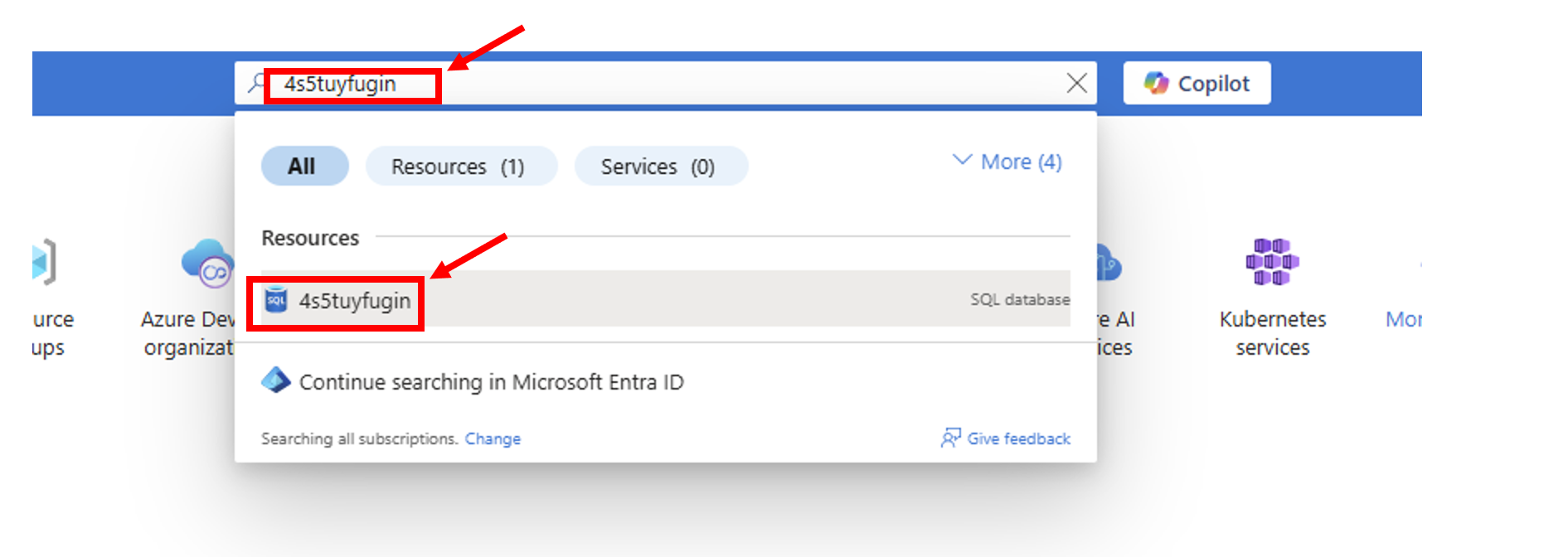
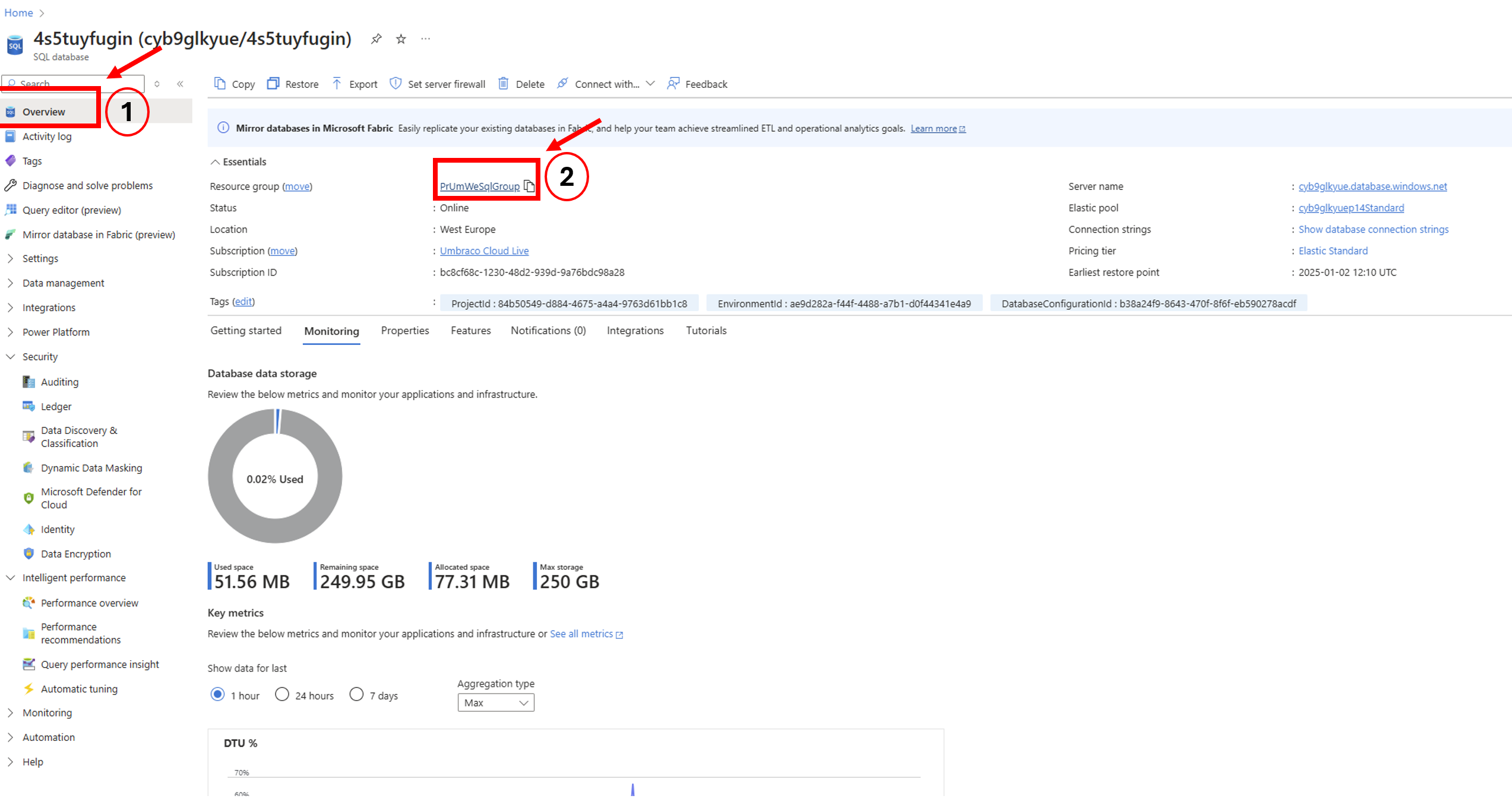
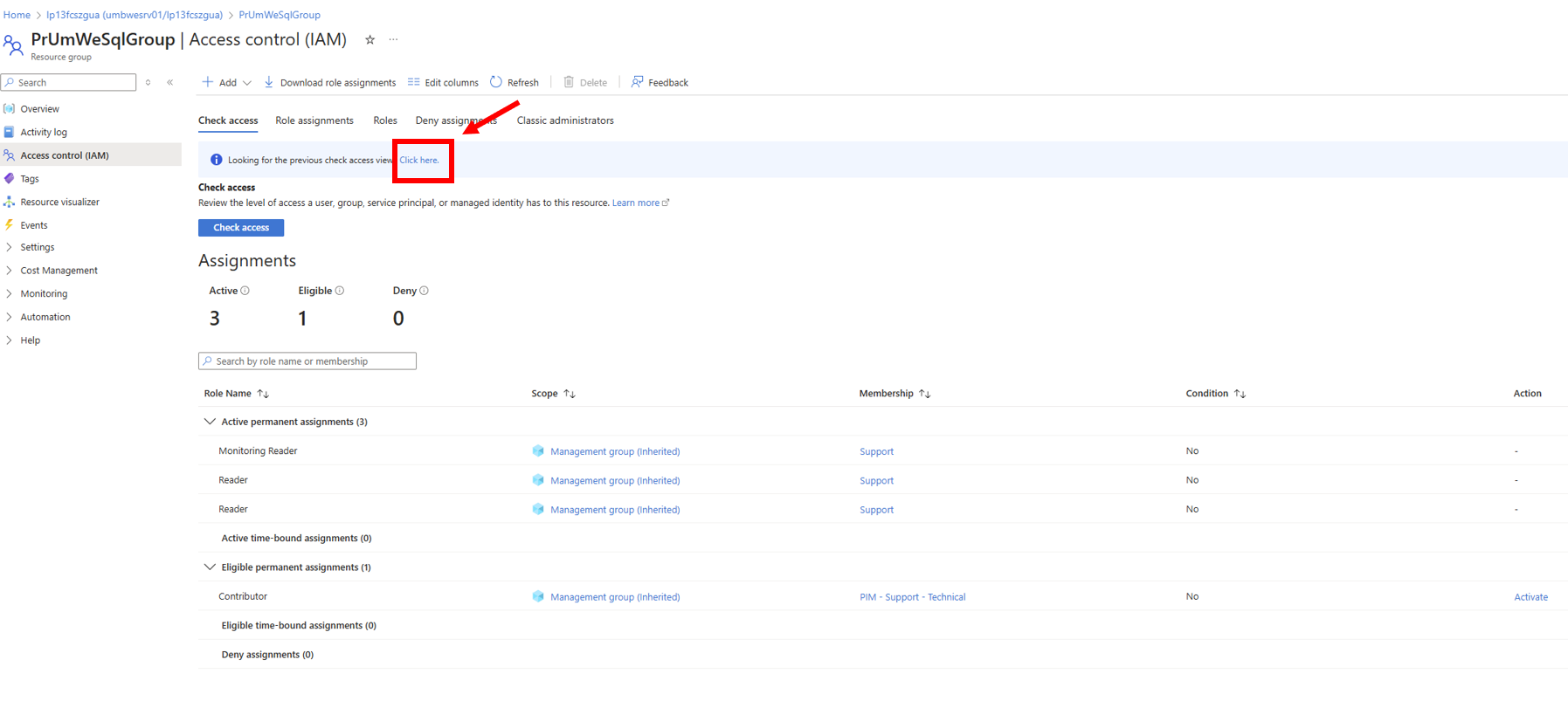
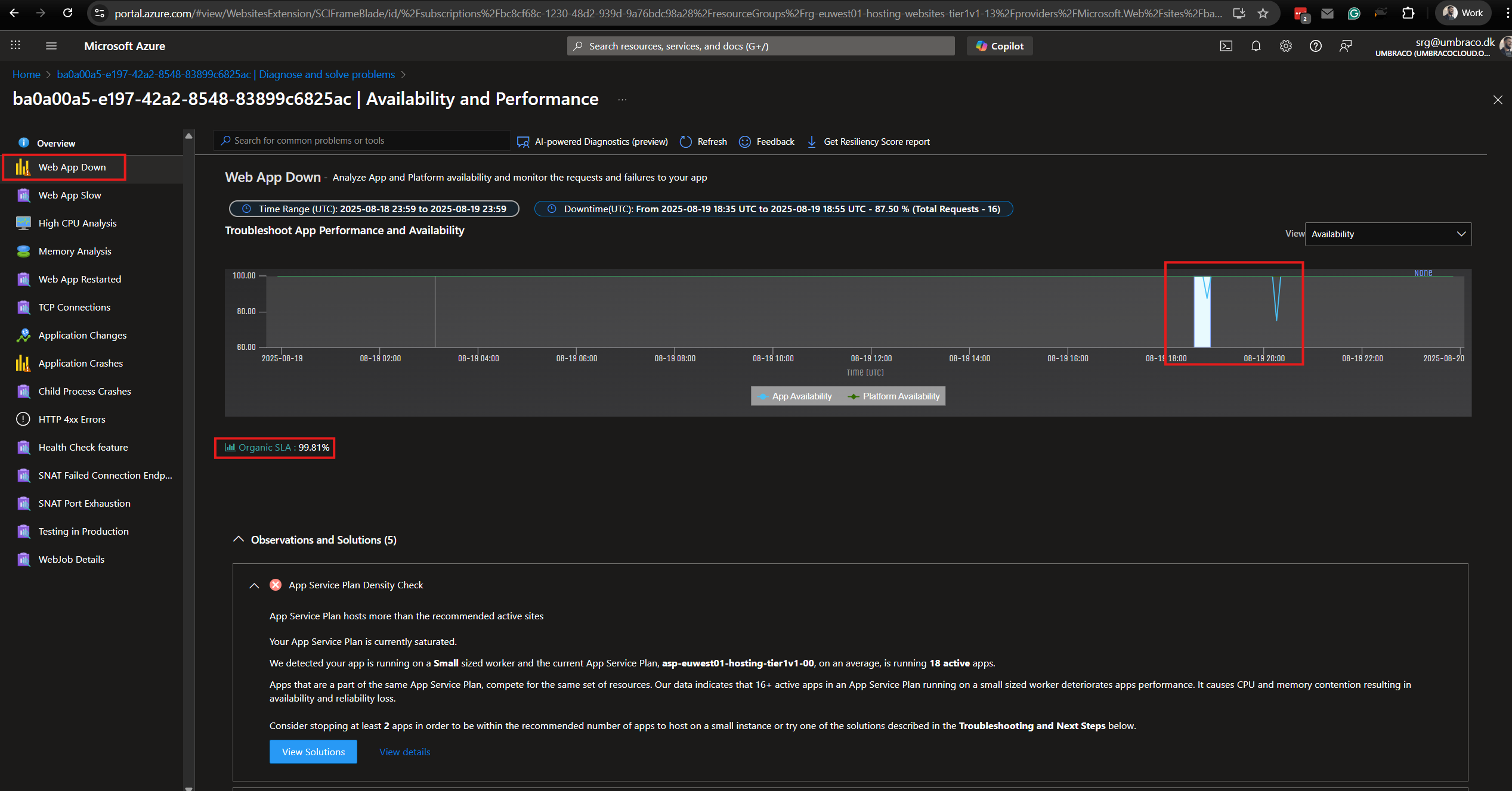
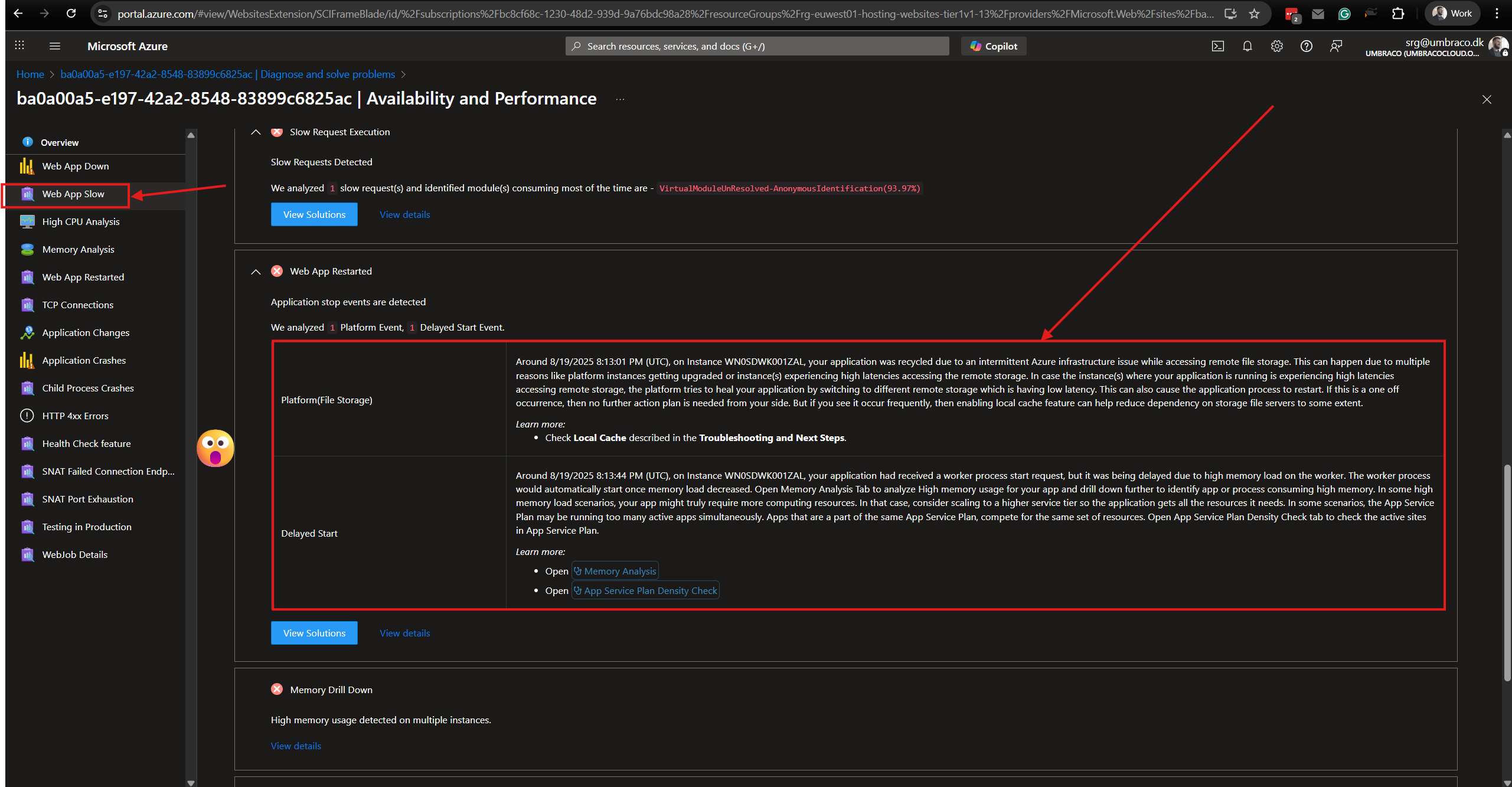
Now we can see what happened. We have two different events.
- Platform(File Storage)
This means that the server had trouble talking to its storage (like a shared hard drive in the cloud). To fix it, Azure automatically restarted the application on a healthier connection. This restart is called a "recycle."
For an Umbraco Cloud project, this can mean:
The site might briefly restart, causing a short outage or slow response.
The site might experience a cold boot, meaning that the site starts up from scratch (like turning on a computer that was fully shut down). This usually takes longer because the app needs to load everything fresh into memory.
However, if a restart is performed the Umbraco project enters a weird state where it requires to be restarted before it starts working again - this is something that is happening constantly on Umbraco Cloud.
- Delayed Start
This means that the Umbraco Cloud site didn’t start right away after a restart — the platform waited before bringing it fully online.
This can happen if Azure is managing resources, applying updates, or ensuring storage/services are ready.